

|
Evolusi konstan pendekatan Machine Learning (ML) selama 20 tahun terakhir telah membawa praktik dan penelitian ke terobosan dalam perkembangan teknologi di berbagai bidang (Jordan dan Mitchell 2015 , hlm. 255). Sejak pembuatan dan penambangan data menjadi lebih layak dan sejumlah besar daya komputasi menjadi jauh lebih mudah diakses dan terjangkau dalam dekade terakhir, metode ML, dengan kemampuannya untuk secara otomatis memecahkan masalah dengan set parameter yang besar, semakin banyak diterapkan di banyak daerah (Delen et al. 2013 , hal. 1152). Dalam beberapa tahun terakhir, metode Deep Learning (DL), bagian dari metode ML, telah mendapatkan popularitas yang lebih besar, terutama karena ketersediaan data kompleks dalam jumlah besar (Agarwal dan Dhar 2014 , hal. 444). Tidak dapat disangkal bahwa Ilmu Komputer terutama akan mendorong kemajuan teknis dari teknologi ini. Industri juga tampaknya sangat tertarik dengan kemajuan metode ini, seperti yang ditunjukkan oleh proyek-proyek seperti Alpha Go dari Google (Silver et al. 2017 ). Namun, metode ML jauh lebih dari sekadar alat khusus TI dan dapat berguna untuk dukungan keputusan, inferensi pengetahuan, dan otomatisasi proses untuk banyak area industri yang berbeda. ML sedang dalam perjalanan untuk menjadi teknologi utama dalam transformasi digital yang bertujuan untuk meningkatkan produktivitas dan mendorong penemuan baru di banyak industri (Jain et al. 2018, p. 250). Untuk mencapai tingkat inovasi yang lebih tinggi dan tetap kompetitif di pasar, pelaku industri tradisional mungkin perlu memungkinkan karyawannya untuk menerapkan metode analisis yang lebih mendalam, terutama terkait perkembangan di bidang Artificial Intelligence (AI) dan ML (Aleksander 2017 ). Namun, tanpa pedoman teoretis tentang cara menerapkan metode ML yang berbeda pada masalah sosio-teknis industri yang lebih kompleks dan spesifik, apakah tujuannya adalah penyimpulan pengetahuan yang berharga untuk keputusan strategis atau optimalisasi proses bisnis, perusahaan dari industri di luar TI akan terus-menerus tertinggal di belakang perusahaan IT besar yang menghadapi monopoli yang akan segera terjadi. Mengenai penelitian tentang metode ML, Ilmu Komputer memenuhi perannya dalam mempelopori pengembangan metode rekayasa dan penelitian mendasar di bidang algoritma. Dalam hal ini, penelitian Sistem Informasi (SI) harus melihat perannya dalam transfer pengetahuan teoritis dari pembelajaran mesin ke aplikasi yang memecahkan masalah (industri) tertentu, dengan tujuan memajukan teori SI serta membantu praktisi dalam menerapkan metode ML. , “untuk mengelola dan mendukung TI atau inisiatif bisnis yang mendukung TI dengan sebaik-baiknya.” (Benbasat dan Zmud 2003 , hal.192). Sementara Ilmu Komputer dan teknik sangat terlibat dengan kemajuan teknologi ini, tampaknya peneliti IS tidak sepenuhnya menerima kemungkinan baru. Lebih dari 30 tahun yang lalu, Straub ( 1989 ) mengajukan pertanyaan apakah penelitian IS mencerminkan dirinya sendiri secara kritis. Sebagai teknologi bergeser lebih ke arah sistem otomatis dan otonom dan transformasi digital menembus setiap industri, penelitian IS harus mempertimbangkan membayar tingkat perhatian yang diperlukan untuk perkembangan teknologi saat ini (Boudreau et al. 2001 ). Secara khusus, bidang ML tidak boleh dikecualikan dari pertimbangan selama proses ini (Maass et al. 2018). Dalam beberapa tahun terakhir, cendekiawan senior IS telah merenungkan integrasi metode analisis yang lebih kuat dan apakah akan menyambut mereka dengan skeptis atau merangkul mereka dengan tangan terbuka. Misalnya, beberapa sarjana telah menyerukan integrasi Big Data yang lebih kuat namun ketat dan metode analitis yang terhubung, seperti ML, dalam penelitian IS (misalnya, Abbasi et al. 2016 ; Maass et al. 2018 ), dan telah mendorong bidang tersebut untuk “rangkul tantangan dan klaim wilayah kami” (Goes 2014 , hal. viii). Meskipun ada banyak diskusi tentang data dan ML, masih belum jelas sejauh mana disiplin IS telah beradaptasi dengan fenomena teknologi ML yang muncul. Poin penting, yang secara teratur ditekankan oleh para sarjana senior, adalah bahwa penelitian IS harus berurusan dengan dan menganalisis artefak TI secara khusus karena, terutama dengan cara ini, bisnis dan masyarakat dapat mengambil manfaat dari penelitian kami (misalnya, Benbasat dan Zmud 2003 ) . Karena metode ML menawarkan banyak kemungkinan untuk agregasi, pemrosesan, dan analisis data, metode ini juga tampaknya memberikan peluang yang sangat baik untuk aplikasi dalam proyek penelitian. Hal ini terutama berlaku untuk penelitian tentang fenomena yang relevan dengan IS, yang intensif data atau terkait dengan penelitian tentang topik terkait AI atau keduanya (mis., Abbasi et al., 2016 ; Maass et al., 2018; ). Bahkan sebagai instrumen non-analitis, ML dapat digunakan untuk membangun sistem yang sangat fungsional dalam studi eksperimental atau studi kasus (misalnya, Benbasat et al. 1987 ), yang secara signifikan dapat meningkatkan validitas studi tersebut. Dalam konteks ini, penting untuk disadari bahwa ML tidak dapat menjadi alat universal untuk semua tujuan, meskipun batasan dari apa yang mungkin dengan ML tampaknya juga belum diuji secara memadai. Singkatnya, perluasan penggunaan ML sebagai instrumen penelitian berpotensi memperkaya proyek penelitian secara metodologis. Selain itu, juga dapat meningkatkan relevansi temuan yang dihasilkan dan pada saat yang sama dapat membantu memenuhi misi penelitian SI berkaitan dengan praktik: untuk memberikan panduan dan membenarkan aplikasi dan penerapan untuk memastikan “bahwa apa yang ditemukan dan diterapkan sebenarnya `benar' `` (Benbasat dan Zmud 1999 , hal. 12). Dalam konteks refleksi diri dari disiplin IS, kami, oleh karena itu, bertujuan untuk memeriksa keadaan penelitian saat ini di IS untuk ML dan mencoba menjawab pertanyaan-pertanyaan berikut dalam konteks penelitian IS:
Karya ini bertujuan untuk memahami konteks adopsi dan penerapan ML (non-) sebagai teknologi mutakhir dalam penelitian ilmiah di bidang SI. Di luar itu, makalah ini juga bertujuan untuk membuat penelitian SI lebih mengetahui topik penerapan metode ML berdasarkan tinjauan bibliografi dan analisis scientometrik kami selanjutnya (Leydesdorff 2001 ; Khan and Wood 2016). Dengan menjawab pertanyaan penelitian kami yang disebutkan di atas, kami bertujuan untuk berkontribusi pada penelitian SI dalam beberapa cara: (1) Dengan menganalisis masalah yang tampak dengan penerapan ML dalam penelitian IS melalui tinjauan bibliografi bibliografi secara kuantitatif, kami menekankan bahwa masalah nyata bertahan. (2) Dengan melakukan survei nasional yang melibatkan 110 sarjana IS di Jerman, kami memeriksa dengan cermat alasan inti masalah ini dan menjelaskan bagaimana komponen ini menghalangi penerapan metode ML dalam penelitian IS. (3) Kami menyimpulkan artikel ini dengan menyarankan implikasi dan kerangka penelitian terstruktur untuk menggabungkan pendekatan berbasis teori klasik dengan pendekatan ML yang lebih berorientasi pada data dalam penelitian IS. Dengan mengerjakan pertanyaan penelitian kunci untuk pekerjaan di masa depan, Bagian selanjutnya dari artikel ini adalah sebagai berikut: “ Latar belakang teoretis ” memberikan latar belakang teoretis ML dan deskripsi tingkat tinggi tentang cara penerapannya. “ Metodologi ” menjelaskan metodologi kami. Setelah itu, “ Hasil ” menyajikan hasil tinjauan bibliografi kami dan analisis scientometrik selanjutnya. Selanjutnya, kami menempatkan temuan ini ke dalam konteks dalam " Diskusi " dan mendapatkan tantangan utama untuk adopsi skala luas dan penerapan ML sebagai instrumen penelitian di IS. Atas dasar ini, kami melanjutkan dengan menyajikan implikasi dari temuan kami untuk penelitian dan praktik SI dalam " Implikasi untuk penelitian dan praktik "”. Pada langkah terakhir analisis kami, kami memperoleh agenda penelitian untuk penelitian ML terapan di IS dalam “ Penelitian lebih lanjut ”. Penutup " Kesimpulan " menguraikan keterbatasan penelitian kami dan menawarkan saran tambahan untuk penelitian lebih lanjut dan ringkasan temuan kami. Gambar 1 menunjukkan taksonomi metode pembelajaran mesin dan contoh algoritma yang sesuai pada Tabel 1 ).Gambar 1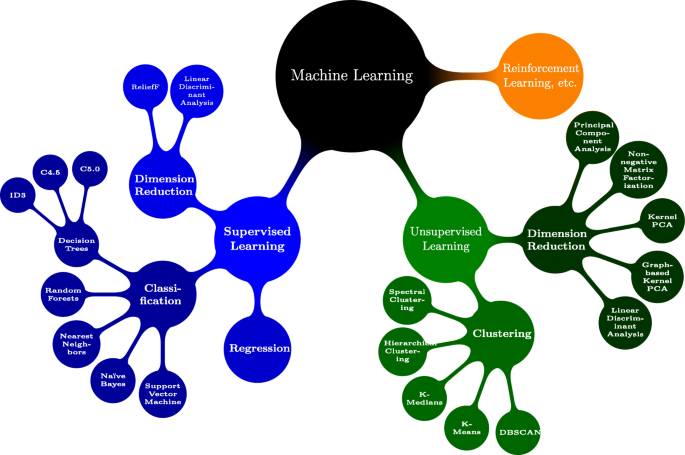 Ilustrasi Skema Taksonomi dan Contoh Algoritma dalam ML Menurut Karya Russell dan Norvig ( 2016 ) dan Bishop ( 2006 ) Gambar ukuran penuhPembelajaran yang diawasi menggunakan fitur (yaitu, atribut data yang menjadi perhatian) untuk memprediksi atau mengklasifikasikan label yang benar (yaitu, nilai target atau kebenaran dasar) (misalnya, Hutson 2017 , hal. 19). Model pembelajaran yang diawasi umumnya dilatih pada data berlabel dan membuat kesimpulan statistik berdasarkan model yang terlatih. Dalam hal ini, model pembelajaran terawasi dapat melayani tugas klasifikasi atau tugas prediksi. Algoritma yang terkenal untuk klasifikasi antara lain: Hierarchical Naïve Bayes (Wang et al. 2011 ), Algoritma Decision Tree (van Riessen et al. 2016 ), Random Forest (Sokolova et al. 2017 ), Support Vector Machine (SVM) ( Piri dkk. 2018 ).Dalam pembelajaran tanpa pengawasan, algoritme mencari pola dalam fitur kumpulan data tanpa mempertimbangkan label kebenaran dasar, jika ada sama sekali (Hutson 2017 , hlm. 19). Dalam hal ini, pembelajaran tanpa pengawasan memungkinkan penemuan pengetahuan bahkan dari data yang tidak berlabel. Deteksi pola ini mungkin memiliki berbagai tujuan, di mana terdapat subbidang pembelajaran tanpa pengawasan yang berbeda. Pengelompokan merupakan salah satu dari subbidang ini dan dapat didefinisikan sebagai prosedur yang mengelompokkan titik data dalam kumpulan data besar berdasarkan properti serupa (Gerber dan Horenko 2015, p. 1). Model algoritma ini tidak dilatih pada data yang diklasifikasikan sebelumnya, sehingga algoritma terikat untuk menemukan pola dalam data yang diproses. Algoritma yang terkenal dalam konteks clustering misalnya K-Means (Shahrivari dan Jalili 2016 ), DBScan (Junior dan da Silva 2017 ), Self-Organizing Maps (SOM) (Valle et al. 2017 ), BIRCH (Lorbeer et al. al. 2018 ) dan Model topik (Gong et al. 2018 ). Subbidang lain yang sering dianggap sebagai bagian dari pembelajaran tanpa pengawasan adalah pengurangan dimensi. Tujuan pengurangan dimensi adalah untuk menemukan representasi kompak dari data dimensi tinggi dengan mengurangi jumlah variabel fokus (Roweis dan Saul 2000, p. 2323). Subkategori penting dari metode yang berlaku di setiap subbidang dalam ML adalah Jaringan Syaraf Tiruan (JST). Terutama dalam dekade terakhir, peningkatan besar sehubungan dengan akurasi dalam pemecahan masalah otomatis untuk masalah komputasi yang kompleks seperti klasifikasi dalam dataset MNIST (Deng 2012 ), tidak akan mungkin terjadi tanpa ketersediaan data dan daya komputasi yang terus meningkat. . Karena ANN mungkin merupakan pembangkit tenaga listrik terbaru dari solusi efisien untuk banyak masalah dunia nyata, hype saat ini di sekitar ML mungkin telah berkontribusi besar pada terobosan ANN, terutama Deep Neural Network (DNN)Catatan kaki3 arsitektur.MetodologiBagian ini menjelaskan proses penelitian kami secara rinci. Inti makalah ini adalah identifikasi terstruktur, evaluasi, dan analisis publikasi yang relevan untuk menjawab pertanyaan penelitian yang ditentukan. Niat kami bukan untuk memberikan tinjauan historis yang merangkum semua makalah ML di IS. Sebaliknya, kami bertujuan untuk menjawab pertanyaan penelitian RQ 1.1 dan RQ 1.2 dengan menganalisis munculnya literatur yang melibatkan metode ML di IS dan perkembangan dalam literatur IS selama sepuluh tahun terakhir (" Tinjauan bibliografi ") dan dengan menggabungkan hasil analisis literatur ini dengan temuan dari survei nasional sarjana IS (" Analisis survei "). Tinjauan bibliografi dan analisis scientometricUntuk menjawab pertanyaan penelitian kami, kami menggunakan analisis scientometric berdasarkan tinjauan bibliografi (Leydesdorff 2001 ). Scientometrics dapat dipahami sebagai studi (kuantitatif) penelitian, yang memberikan informasi tentang pola publikasi dan kemajuan suatu bidang (Lowry et al. 2004). Terutama mengingat penilaian keadaan penelitian ML saat ini di IS dan pengembangan lebih lanjut dari disiplin, analisis scientometric dapat menghasilkan wawasan sistematis dan analitik yang dapat membantu untuk secara kritis mencerminkan bidang dan memajukannya. Beberapa sarjana senior IS telah menganggap analisis scientometric sebagai langkah evaluasi yang tepat dan diperlukan yang dapat membantu mengkonfirmasi asumsi tentang inefisiensi dalam disiplin penelitian dan pada akhirnya berkontribusi untuk meningkatkan posisi disiplin (Lowry et al. 2004 , 2013 ; Lewis et al. 2007 ; Straub 2006 ). ). Oleh karena itu, kami bertujuan untuk melakukan beberapa analisis scientometric yang meliputi pola publikasi di jurnal SI, pola kerjasama publikasi ML di bidang SI serta pemanfaatan metode ML. Untuk melakukan analisis mendalam, karena itu kita harus menggunakan tinjauan bibliografi komprehensif yang akan memberikan dasar untuk analisis scientometric kami. A bibliographic review should follow established guidelines, especially if it deals with novel methods (Webster and Watson 2002). Therefore, we followed the guidelines for bibliographic reviews in IS proposed by Webster and Watson (2002) and Kitchenham (2004), and Wolfswinkel et al. (2013). As the first step, the guidelines propose choosing suitable selection criteria for the literature search. In our context, this includes the selection of keywords that either represent important and well-known machine learning algorithms or methods. Table 2 shows the relevant keywords. Subsequently, the next task is the selection of possible databases. We limited ourselves to a well-known selection of databases. These include: “AIS electronic library (AISeL)”, “Google Scholar”, “INFORMS database”, “ScienceDirect”, “SpringerLink” and “Taylor & Francis Online”. We will describe these in detail later in this work. Step three is the actual search for literature, including querying the selection of databases with the selected keywords and search parameters. The final step comprises the review of the literature. This is the initial exclusion of non-relevant literature and the selection of relevant literature based on the title, keywords, abstracts, and articles’ content. Based on our research question, we have selected the most important journals in Information Systems based on the definitions of the Association of Information Systems (AIS). At the current state, the AIS constitutes “the premier professional association for individuals and organizations who lead the research, teaching, practice, and study of information systems worldwide.”.Footnote4 In its role as a leading organ of the IS discipline, the AIS has also defined a list of top journals of the IS discipline, which is limited to those in the IS field.Footnote5 Similar to other works that analyze the IS field (e.g., Trieu 2017; Khan and Triers 2018), we use the Senior Scholars’ Basket of Journals as a basis to assess the current state of the IS discipline through analysis of its core journals. We add Electronic Markets (ELMA) and Decision Support Systems (DSS) as proxies for the most important journals in our research domain related to to Computer Science topics. Table 2 shows this review focuses on papers in any of the top or high-ranked IS journals (the Senior Scholars’ Basket, plus ELMA and DSS).Table 2 Review processFull size tableThe selection of the journals correlates with rankings such as the VHB-Ranking (German Academic Association for Business Research) or the CABS-Ranking (Chartered Association of Business Schools), which may be understood as a quality assurance measure for scholarly publications (Mingers and Yang 2017, p. 323). Thus, the selection process of the articles implicitly assumes quality assurance within the selected journals. Notably, this assumption is not undisputed according to Lehmann and Wohlrabe (2017) or Seiler and Wohlrabe (2014). At this point, it should be mentioned that this quality assurance can be seen critically in the context of more technical research in IS, which includes the application of more complex ML methods. IS scholars who are rejected within the review process in one of these outlets that are considered as high-quality outlets by senior IS scholars (i.e., they are not accepted within the prevailing IS paradigm) proceed and often get the papers published in Computer Science journals, such as IEEE Transactions or in journals linked to the IEEE Computational Intelligence Society; these journals have much higher impact factors and are from a scientometric perspective (Leydesdorff 2001; Khan and Wood 2016) as relevant as the Basket journals but may (falsely, e.g., Lowry et al. 2004, p. 36) not be judged as strong contributions to IS research. Regarding data consistency and relevance across the sample, only publications containing the keywords from Table 2 in their abstract, title, or main text, were retrieved and analyzed. To validate that these rules were met, we used a two-layered approach, out of which an algorithm performs the first one, and a manual inspection is used as the second layer. To automatically query the databases, we developed a proprietary application.Footnote6 Setelah file .pdf diambil dengan menanyakan database dan mengunduh file yang sesuai dengan artikel, kami menggunakan algoritme kami untuk menganalisis file .pdf ini. . Algoritme kami membuka semua file Portable Document Format (.pdf) untuk langkah validasi pertama dan menandai file yang berisi kata kunci pilihan kami. Pada langkah validasi kedua, kami memeriksa kertas yang diberi tag secara manual untuk memeriksa validitas klasifikasi.Survei di antara para sarjana ISSebagai sarana analisis tambahan, survei semi-kuantitatif digunakan untuk memahami lebih baik bagaimana ML sebagai instrumen penelitian dirasakan di antara komunitas IS. Semua peneliti IS dari fakultas IS Jerman diundang untuk berpartisipasi dalam survei ini. Kuesioner menanyakan pertanyaan umum tentang pengembangan karir dan pertanyaan spesifik tentang area subjek ML, terutama transparansi (atau ketidakjelasan) yang dirasakan dari berbagai metode ML. Temuan yang relevan dijelaskan di bagian kedua dari hasil. Kuesioner lengkap, serta visualisasi statistik yang terperinci, dapat ditemukan di Lampiran . HasilUlasan bibliografiKami melakukan tinjauan bibliografi antara Juli 2018 dan Juli 2020. Hasil awal kueri basis data kami mencakup 1.922 makalah. Setelah pemfilteran file dengan pencocokan kata kunci menggunakan algoritme berpemilik, kami mempertahankan 493 makalah yang tersisa. Kami kemudian secara manual memeriksa teks lengkap dari publikasi yang tersisa. Sebagai hasil akhir dari tinjauan bibliografi bibliografi, kami mendapatkan sampel 441 makalah yang tersisa. Tinjauan bibliografi artikel jurnal hanya menunjukkan sejumlah kecil kontribusi yang berkaitan dengan kata kunci yang sesuai (lihat Tabel 2 untuk daftar kata kunci). Tabel 3 menunjukkan hasil penelitian kepustakaan dan validasi scientometric, dirinci berdasarkan tahun dan jurnal yang diperiksa. Tabel 3 Review jurnal dan jumlah artikel menurut tahunMeja ukuran penuhAnalisis literatur menunjukkan gambaran yang serius tentang jurnal-jurnal dalam Keranjang Cendekiawan Senior. Hanya beberapa artikel di jurnal ini yang membahas langsung penerapan metode ML. Di jurnal IS peringkat atas, seperti ISR ??dan MISQ, hanya segelintir sarjana yang menerapkan ML dalam proyek penelitian mereka. Teladan di antaranya adalah karya-karya Gong dkk. ( 2018 ), Arazy dkk. ( 2016 ) dan Meyer et al. ( 2018). Sebaliknya, jurnal ELMA menghitung publikasi dua kali lebih banyak daripada ISR. ISJ tampaknya menjadi satu-satunya jurnal berperingkat tinggi yang menerbitkan sejumlah besar artikel penelitian yang berhubungan dengan penerapan metode ML selama sepuluh tahun terakhir. Pada titik ini, harus disebutkan bahwa jurnal diterbitkan pada interval yang berbeda. Oleh karena itu, kami menormalkan hasil kami sesuai dengan frekuensi publikasi setiap jurnal. Tabel 3 menunjukkan angka yang dinormalisasi dalam “Norma.” kolom. Against this background, the number is to be regarded as relative. However, we argue with the absolute number to allow comparability with other literature analyses in IS. Notably, yet not entirely surprising, is the number of publications within the DSS journal with an application of ML methods: We found that 272 articles have been published over the past ten years within this journal, which is three times as many publications as in the ISJ. Notwithstanding, Table 3 shows a trend over the last years in the publication rate of ML in high-tier IS journals. From 2009 until 2019 the publication rate has increased approximately by 4.2 (? : 4.2182 at p <?0.01) papers each year based on OLS regression analysis in Table 3.Footnote7 This result indicates a growing interest in ML within the IS research domain. On closer inspection, journals with a more technical focus like DSS, or top-journals like ISJ, that state “publishing high quality, yet risky, papers that help to move the IS field forward” (Davison et al. 2012; Davison 2017) as part of their mission and tradition are highly benefiting from this growing interest.Nonetheless, it seems that it has been difficult in the past to publish research articles that apply ML methods as research instruments in top IS journals according to our results. Similar observations concerning the application of ML in research have been made by Krauss et al. (2017) in the neighboring discipline of finance. The stagnation in applied ML research may be a problem that is originated in the reliance of IS research on standard quantitative methods, which is strongly influenced by organizational studies (Basden 2010). Based on the assumption that the disciplines influence each other, we argue that additional information about the collaborations and affiliations of researchers to different research areas within our sample would facilitate understanding. In line with Khan and Wood (2016) we argue that collaborative behavior influences the research diversity with all its virtues and thus influences the content, performance, and output of those involved in its boundaries (Vidgen et al. 2007). Therefore, we analyze the collaborating research disciplines in applied ML research in IS in the next step. To classify our results, we analyzed the collaborating disciplines within our sample of 441 research articles. For this purpose, we extracted the additional information regarding the authors of the articles from their websites, classified their affiliation, and organized the information on collaboration within a matrix. Figure 4 shows a clear pattern regarding the collaboration structure for papers that apply ML in IS research. Of the 441 papers, 224 have been published by heterogeneous teams. Homogeneous teams have published 217 papers (in relative terms: 38% Information Systems, 25% Management Science, 13% Computer Science, 11% Engineering, 5% Industry research, 8% remaining research fields, see Fig. 4). To identify the collaborations, we have counted each connection in the teams once, which means that if several scholars of the same discipline research area are listed in the article, it was counted as one occurrence. We discovered strong scientific collaborations between IS scholars and scholars from Management Science, Industry research, and Computer Science. The finding shows a congruency with the ideas of Basden (2010) that IS research tends to have more collaborations with departments from business schools and management science, rather than departments from its other neighboring discipline, Computer Science. Noticeable in our analysis in the context of ML is the high participation of companies. Altogether, IS journals represent a large number of disciplines in the context of ML. We also discovered exotic papers such as Swiderski et al. (2012) from the field of military research. To give a clear and informed answer to the question of which analytical research instruments dominate IS research, we decided to employ a trend analysis and compare other statistical methods used in IS research. For this reason we developed a data mining algorithm to extract all necessary information from the “Association for Information Systems” (AIS) online library. In line with Recker (2013) and Chen and Hirschheim (2014) IS research can be systematized into three categories: quantitative, qualitative and mixed (Recker 2013, p. 66). These categories are an appropriate starting point because IS scholars use diverse methods and theoretical lenses to explore the phenomena of research interest. We add a fourth category, namely ML. This enables us to analyze the papers according to the classical methods, such as regression (Goodhue et al. 2017, p. 667) or partial least squares regression (Marcoulides et al. 2009, p. 172). Within these four categories, our algorithm assigns the applied research method to its corresponding category. To assign the right category for each used research method, we use the work of Chu and Ke (2017) as guidance. In line with Recker (2013) and Chu and Ke (2017), this analysis shows a similar relative trend for quantitative, qualitative, and mixed methods. The depicted analysis is both congruent with our findings in Tables 3 and 4 and with the idea of Basden (2010), that IS is influenced by a variety of different disciplines. While Fig. 2 as well as Table 3 show a rise in the use of ML methods, these publications seem to be mostly accepted in conference proceedings or 2nd-tier journals, such as DSS and EM, but not in journals from the senior scholars’ basket of journals, such as JIS, ISR or MISQ. Although the philosophical notion of “spheres of meaning” take on our discipline by Basden (2010) is certainly disputable, it may explain why cutting-edge IS research falls behind in the application of more recent and probably more advanced analytical and data-driven methods. Fig. 2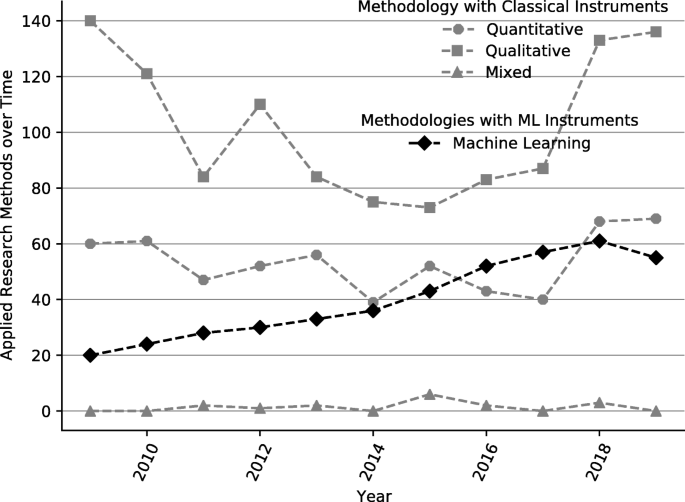 Trend of Research Methods Used in Publication in Selected Top IS Conferences and Journals Vs. Machine Learning as Instrument. Time frame of the publications 01/2009 - 12/2019 Full size imageTable 4 Scholar affiliation/collaboration matrix in is research works with ML methodsFull size tableSurvey analysisWith regard to Basden (2010), it appears that the major concern of disciplines from organizational studies is not the development of stronger different analytical or data-driven approaches, but the assurance of the validity of social, economic and formal theories (Basden 2010). Since IS research has its roots in organizational studies, the quantitative approaches that are applied are the ones that have been accepted as valid for a long time, which may make it more difficult for newer methods. One possible cause of the lack of application of certain ML methods is their black box characteristic, which means that the processes between input and output are opaque, such that it obstructs intuitive interpretability of a method. As put forth by a senior IS scholar lately, “inscrutability can hamper users’ trust in the system, especially in contexts where the consequences are significant, and lead to the rejection of the systems.``(Rai 2020, p.1). To verify our notion about the connection between a lack of interpretability and a lack of applied ML research in IS, and to assess the perceived black- or white box-characteristics (i.e., intuitive interpretability) of the applied ML methods by IS scholars, we conducted a short semi-quantitative survey with IS research scholars in Germany. The invitation was sent out to all members of German IS faculties. At this point, it must be emphasized that education systems in different countries in the IS community deal differently with ML, which is why the sample can be considered indicative only. We asked 364 scholars and received 110 answers (response rate of 30%). We let IS scholars rank different ML methods on a scale of 1 to 5 (1 = White box to 5 = Black box). Regarding the demographics, most participants in the survey are researchers from the IS field, male and working as research assistants. With respect to their research orientation in the context of the area of highest education, the largest group of participants have studied IS with 68.25% (accounting and finance 1.59 %, econometrics 1.59 %, logistics 3.17%, statistics 3.17%, engineering 4.74%, other 4.74%, management (science) 4.74%, Computer Science 7.93%). The largest proportion is male with 85.7% (female 12.7% and other 1.59 %). The survey was mainly filled out by Doctoral or PhD candidates 65.1% (Prof. Dr. 1.11%, research assistant (without being Dr. or PhD candidate) 20.65% and Other 3.17%). The data collected reveals that 93.2% of the participants did not have dedicated ML training courses in their PhD program. However, 74.1% say that they would like to have a training course in ML. In line with our RQ 1.1, we asked about the relevance of ML in IS. In response, 85.4% of researchers stated that ML is absolutely relevant. Furthermore, 77.4% of the researchers also assume that ML is relevant or absolutely relevant for the progress of the IS discipline. Also, 85.4% of researchers considered the relevance of ML for IS research to be persistent in the future. We continued our analysis by calculating a score measuring the degree of the black box characteristics based on the IS researchers’ assessment. Figure 3Footnote8 shows ML methods sorted according to their transparency (K-Medians = White box; ANN = Black box) based on the IS researchers’ assessment.Fig. 3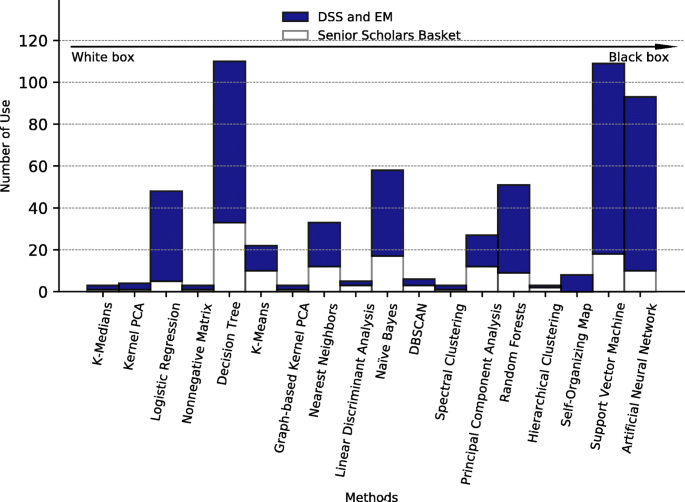 Usage of ML Methods in IS Publications. The methods are ordered according to their degree of the black box characteristics (top = White box method, bottom = Black box method) Full size imageFigure 3 shows that it is generally accepted that ANN are considered a black box. On the other hand, Decision Trees are more likely to be rated as a white box method. The comments from the open text fields of the survey reveal that Decision Trees are seen as a white box because they provide metrics that are simple to interpret (e.g., entropy, information gain). Our investigation shows that most of the works in our original sample (N = 441) that are published in the Senior Scholars Basket of Journals deal with simple and well-known approaches like Naïve Bayes and Decision Tree algorithms. Approaches with lower transparency, such as ANN, BIRCH model, or SOM, are used less often or not at all. To determine the publication rate in top journals in relation to the method complexity level (1 = White box to 5 = Black box), we performed a logistic regression. In the case of multiple applied ML-methods, the method with the highest degree of non-transparency is considered in our analysis. $$ \text{Publication in Top-Journal}(y_{1|0}) = \alpha + \beta_{1} \text{Complexity} + \varepsilon $$(1)The odds ratio (0.8193) indicates that if the degree of the opaqueness of the applied ML method increases by one unit, the probability of a publication in a top journal decreases by 18.07%. These findings are in line with many overview papers on ML in the field of IS, such as Chen et al. (2012), Dhar (2013), Abbasi et al. (2016), and Maass et al. (2018). Compared to more traditional statistical methods used in IS, such as partial least squares regression (PLS regression) or structural equation modeling (SEM), ML methods are relatively sophisticated (Table 5). Table 5 Logistic regression for acceptance determination in top-journals considering the ML-Method complexityFull size tableIn fact, advanced ML models can capture any functional relationship between variables given enough data (Pearl and Mackenzie 2018). Although the capabilities of ML methods often go beyond what is achievable with traditional methods, a lack of transparency leads to problems with the intuitive interpretability of ML methods. Due to this circumstance, it is not a surprise that ML methods are not widely used in IS research, which supports our hypothesis that the black-box characteristic and a lack of interpretability may be reasons for the low application rate of complex ML methods in top IS outlets. DiscussionOur analysis revealed only a small number of articles that apply ML methods in IS top journals. The number of articles dealing with ML in the IS domain has increased over the years, which suggests that this is a research area that is increasingly attracting academics’ interest, especially in the past two years. We share the concern “that the IS research community is making the discipline’s central identity ambiguous by, all too frequently, under-investigating phenomena intimately associated with IT-based systems and over-investigating phenomena distantly associated with IT-based systems” (Benbasat and Zmud 2003, p. 183). One reason for the findings of RQ 1.1 may be that articles that are concerned with or built upon ML methods’ application are rather unpopular among scholars and were excluded in the review process. Due to the low prevalence of ML methods in IS research and the associated low confidence in the robustness, verifiability, and interpretability of the results, a systematic negative bias towards these methods could exist. Due to the perceived lack of insight, articles dealing with or involving ML topics could be difficult to publish in high-ranking journals because articles with traditional methods are preferred. Thus, authors may only be motivated to use classical quantitative methods, as they provide an easily justifiable method and allow a direct result in terms of knowledge gained with a transparent white-box approach. Another possible reason for the findings related to RQ 1.1 may be, of course, that a systematic lack of expertise and understanding of ML methods is present in the domain of IS. This circumstance may be directly related to the analysis in the previous paragraph: If acceptance rates, reviewers or PhD programs tell IS scholars that other research instruments are not equally valuable, researchers will not strive to learn and apply these new methods strenuously and will prefer to use classical quantitative research methods. In addition, our survey findings support the idea that only a few PhD students receive appropriate education in ML methods. From our participants, only 6.78% of the PhD students completed required ML courses during their PhD (see appendix). Consequently, prospective researchers in our field have hardly any contact with these technologies during their training. In contrast, our survey data indicates a clear interest in such courses (74.07% of the participants would like to attend such courses). The integration of ML courses into regular IS-PhD programs could solve this problem and help researchers learn to apply these methods correctly in their early careers. Nevertheless, based on our quantitative data, we cannot tell if researchers, in general, perceive ML methods as hard to learn, hard to apply, not as valuable, or not as interesting as standard quantitative methods. Analyzing the central challenges from the KDD perspectiveWe draw the notion from our scientometric literature analysis results that the underlying issue warrants further qualitative examination. Using the acquired information from our analyses, we identified essential obstacles and challenges for large-scale adoption of ML methods within IS research. We structured insights from the reviewed literature into a total of three central challenges that IS scholars, as well as industry practitioners, should be aware of if they aim to leverage the benefits of ML in research or practice. In principle, these challenges for the application of ML in the field of IS can be systematized along the Knowledge Discovery in Databases (KDD) model (e.g., Fayyad et al. 1996). In general, KDD can be understood as a process guideline for information analysis and knowledge extraction, which is divided into stages from data acquisition to data interpretation. The objective of KDD is knowledge inference such that an end-user may finally gain valuable information that supports them in their attainment of a guideline for the development of methods for making sense of data (Fayyad et al. 1996, p. 37) is also a part of the Data Mining (DM) process (Marban et al. 2009). The KDD model expects the use of input data derived from a dataset acquisition process (Lara et al. 2014, p. 54). The raw data are filtered according to quality criteria, selected according to possible target values, and transformed correspondingly. These essential steps can also be referred to as pre-processing, feature selection, and feature engineering. Subsequently, the selected Machine Learning model will be trained with the prepared data. The interpretation of the data by a user follows and a recursive-iterative process for the fine-tuning of the model may occur until the final model is determined. Although the KDD model poses a helpful guideline, many challenges emerge along with the respective process steps, which we will now address according to the three central challenges we identified: i) data preparation, feature selection, and engineering, ii) model optimization and parameter tuning, iii) results and interpretation of black boxes. Data preparation, feature selection, and engineeringML methods heavily rely on high-quality training data. The work of Baier et al. (2019) shows that for many applications of ML models in practice and science, one of the biggest challenges is data quality (Lee-Post and Pakath 2019). Various factors may determine if the quality of the data to be used is sufficient for the project in pursuit. Among these factors, the properties, structure, and complexity of data samples (Piri et al. 2018, p. 23) may play a huge role while also contextual factors, for example, timestamp of data collection could have an impact on the results. Data generally tend to exhibit noisy parts. That is why data screening, cleansing, and pre-processing need to be performed before ML algorithms can use these data as an input (Basti et al. 2015, p. 22). One major problem resulting from data cleansing is the possibility of losing important information by removing certain parts of the data (Rittgen 2009). As a result, variables generated from data mining models could lead to biases, and misclassifications (Yang et al. 2018, p. 4). Therefore, it is important to realize that it is common practice to dedicate about 80% of the labor and time within the KDD process to data preparation, as a representative survey on a popular data science portal shows.Footnote9 This circumstance shows that there is potential for further research in the area of data preparation to reduce the time consumption of data preparation. This circumstance is linked to the quality of the data. Future research, such as in the field of Resource Description Framework (RDF) can contribute to this (e.g., Benbernou and Ouziri 2017).Besides questions of data quality, privacy concerns play an important role. The relevance of this topic increased drastically from the early history of data privacy since the 1980s (Mason 1986; Bélanger and Crossler 2011). Since these beginnings, the relevance of privacy has increased significantly in theory and practice along with the use and development of more efficient yet data-hungry information processing technology (Pavlou 2011). Especially modern methods from the field of ML can use large amounts of data and even have to do so to achieve sufficiently accurate and generalizable results. But the demand for information privacy leads to new challenges, especially for companies (e.g., Casey et al. 2019), which is expedited by the uncovering of numerous violations of privacy in the past (Culnan and Williams 2011), and the resulting public outcry for more transparency and more restrictive policy regulations such as the. GDPRFootnote10 Calls for better integration of privacy and privacy-compliant IS research from almost ten years ago (Bélanger and Crossler 2011) are thus certainly more relevant today than ever before, especially regarding the usage of ML.In addition to general quality concerns, the sample size is as important for ML algorithms as for traditional quantitative analysis methods because the generalizability of ML algorithms can in most cases only be granted by training on large sets of sample data (Goodhue et al. 2012, p. 983). Since the available data must be used to train the algorithm and test and validate it, it appears to be an equally important task to divide the available sample data into training and testing sets. The complexity further increases when dealing with textual analysis or other NLP tasks, which imbues the problem of unstructured textual sample data (Wang et al. 2015, p. 90). In the case of NLP tasks, the data has to be thoroughly cleaned during the pre-processing phase. For example, punctuation, numbers, and abstract structures such as hyperlinks should be removed before the actual analysis because hyperlinks and punctuation do not themselves add any new information, yet may create noise (See-To and Yang 2017). Also, the data must be continually analyzed to understand what implications the results of an analysis may hold in general (Cnudde and Martens 2015, p. 83). In conflict with this approach is the fact that a lot of real business data, which are provided and analyzed within research studies, can only be retrieved in an encrypted form so that humans can not form a deeper understanding of the data yet still feed their algorithms with it (Martens and Provost 2014, p. 884). While the availability or creation of high-quality data is already a good basis for an accurate predictive model, model performance may still be highly dependent upon the selection and engineering of appropriate features (e.g., Zhang et al. 2017). For example, in unsupervised and supervised learning, feature engineering (e.g., Au 2018) is important for efficient ML-modelling, since provided data - even if it is clean, may warrant unwanted biasesFootnote11 due to its mere structure (e.g., Feldman et al. 2015). Take, for example, two categorical features: city and rating. Both features contain a set of categorical values and both need to be transformed. Nevertheless, while transforming the “rating” feature into an ordinal vector space may lead to an appropriate result, the same procedure would result in an implicit bias for the “city” feature (see Tables 6 and 7Footnote12). Instead, the city feature should rather be one-hot-encoded to avoid such a bias. On the other end, procedures like one-hot-encoding result in a larger feature space, inducing the problem of the “curse-of-dimensionality”, which again may lead to a detrimental degradation of model performance. This problem, on the other hand, should be tackled by dedicated feature selection procedures, that aim to select the most relevant features for the model and ML task at hand (e.g., Zhang et al. 2017; Bach 2017). While many feature selection approaches have been developed until now, research is still very active in this area, and novices may have a hard time finding an appropriate approach for their endeavor. Depending on the feature engineering and selection approaches the ML applicant vows for, model results may vastly vary, which increases the difficulty to determine if the selected methodology is appropriate or not, even for expert reviewers.Table 6 Transformation of the city feature to an ordinal numerical feature space, resulting in an implicit biasFull size tableTable 7 Transformation of the city feature through one-hot encoding, avoiding implicit biasFull size tableOne additional aspect within the context of data preparation is the access to sources with relevant and interesting data, which may explain the high number of publications with industry collaborations (Fig. 4). Examples include collaborations with companies such as Google, Deloitte Consulting, and IBM (Lozano et al. 2017; Fu et al. 2017; Pai et al. 2014). Fig. 4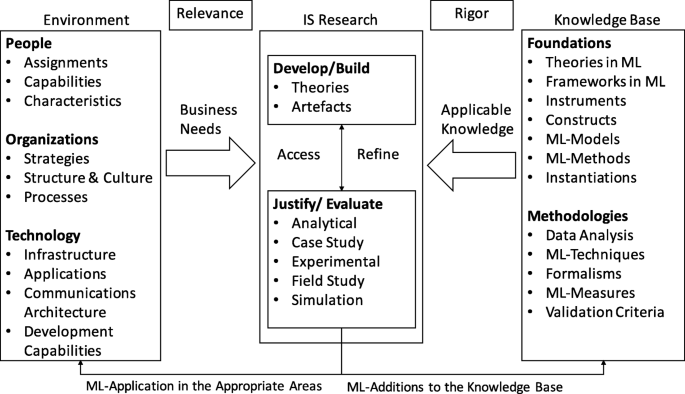 Preliminary information systems research framework based on Hevner et al. (2004) Full size imageModel optimization and parameter tuningThe use of ML algorithms frequently involves careful tuning of learning parameters and model hyperparameters (Snoek et al. 2012, p. 2951). Incoherence with the data, the preparation task is the challenge of model choice. Some scholars have examined this issue in their works, such as Gao et al. (2017, p. 36) or Evermann et al. (2017, p. 139). Whether to choose unsupervised or supervised learning methods depends on the problem environment as well as on the properties of the available sample data (Lau et al. 2012, p. 1245). Only few papers use a combination or layering of several algorithms to test the robustness of their results (Martens et al. 2016, p. 75). This approach may be useful and appropriate for cases in which data needs to be processed in different phases to infer knowledge from the data. This implies higher complexity, which is a reason why such a multi-method approach is rarely used. An important problem of model optimization is the risk of overfitting related to predictive models, which results in overoptimistic results (Siering et al. 2018). To reduce the problem of overfitting, the choice of a simple model can be a possible solution. Scholars and practitioners alike seem to think that the more complex an ML model is, the higher its predictive power and robustness may be. Nevertheless, this may be a fallacy, as pointed out by Cresci et al. (2015). Indeed, it seems that the more complex a model is, the more likely it is overfitting. This should lead us to rethinking this general paradigm of complex architectures or to perhaps turning to simpler, yet more effective models (Cresci et al. 2015). Dengan mempertimbangkan kategori ML tingkat tinggi, pilihan metode dan algoritme pembelajaran ML tidak hanya bergantung pada lingkungan masalah tetapi juga properti dan struktur data yang tersedia. Misalnya, data yang tersedia dapat berupa numerik atau alfanumerik, diskrit atau kontinu, terstruktur atau tidak terstruktur. Poin penting lainnya adalah pilihan parameterisasi model yang tepat - misalnya, memilih k yang tepat untuk model algoritma k-means (Li et al. 2017 , hlm. 83) atau pilihan jumlah lapisan, iterasi, dan ukuran batch data pelatihan untuk JST. Parameterisasi dapat sangat mempengaruhi akurasi dan kekuatan penjelas dari model (Walczak dan Velanovich 2018, p. 117). Selain itu, pemilihan data pelatihan juga merupakan tugas yang sulit, di mana prosedur seperti validasi silang k-fold mencoba menghitung set pelatihan yang sesuai (Topuz et al. 2018 , hlm. 102); Singh dan Tucker ( 2017 , p. 87) atau pemilihan parameter yang tepat untuk Support Vector Machines dari sampel data yang tersedia (Huang et al. 2016 , p. 22). Oleh karena itu, optimasi model dan parameterisasi model ML adalah tugas yang sangat menantang. Di luar itu, para ilmuwan dan manajer harus memecahkan masalah lebih lanjut jika mereka ingin menerapkan metode ML. Tantangan ini dapat dikaitkan dengan kurangnya standarisasi, dalam arti pedoman teoritis untuk menggunakan metode ML pada data ekonomi. Kemungkinan pertanyaan yang mungkin muncul antara lain: Bagaimana seharusnya data disiapkan dan diproses? Metode mana yang paling menjanjikan untuk analisis data yang mendasarinya? Bagaimana seharusnya parameter diatur sehingga model akan mencapai hasil yang dapat diverifikasi dan kuat secara terus-menerus? Kami percaya bahwa analisis ketahanan harus menjawab pertanyaan-pertanyaan ini. Dalam ulasan kami, kami menemukan bahwa hanya beberapa makalah yang melakukan analisis ketahanan model mereka, seperti Wang et al. ( 2015 ) atau Scholz et al. ( 2016 ). Selanjutnya, beberapa makalah menyajikan parameter yang tepat yang digunakan dalam model mereka seperti Pinto et al. ( 2015 ), yang mungkin penting untuk evaluasi dan verifikasi hasil oleh peninjau atau sarjana independen. Analisis semacam itu mungkin menjadi lebih penting ketika penulis mengusulkan untuk menggabungkan metode yang berbeda, seperti (Wan 2015 ).). Oleh karena itu, para sarjana dan praktisi harus didorong untuk tidak hanya menganalisis masalah mereka secara menyeluruh saat menggunakan metode ML tetapi juga untuk melakukan analisis ketahanan dan mengungkapkan pendekatan mereka sehubungan dengan parameterisasi model mereka untuk meningkatkan transparansi dan kepercayaan pada keandalan dan ketahanan analisis mereka. Hasil dan interpretasi: kotak hitamSalah satu tantangan utama untuk adopsi ML skala besar di IS adalah karakteristik kotak hitam dari sebagian besar metode pada waktu proses (Müller et al. 2016 , hlm. 294). Hasil kami, (misalnya, Gambar 8 ), mendukung gagasan ini. Metode ML, terutama JST, sering dipahami dan diberi label sebagai solusi kotak hitam karena mereka memberikan sedikit penjelasan tentang pengaruh variabel independen dan mengapa perhitungan dalam JST menghasilkan hasil yang spesifik (Olden dan Jackson 2002 )., p. 135). Untuk benar-benar memahami mengapa hasil tertentu diberikan mungkin memerlukan aplikasi metode ML untuk mempelajari lebih dalam tentang algoritme pelatihan dari algoritme ML itu sendiri. Terutama dengan munculnya sistem inferensi kompleks yang sangat non-linier dalam bentuk DNN, masalah ini menjadi jelas bagi para ilmuwan dari banyak disiplin ilmu, sampai-sampai tugas membuka kotak hitam bahkan telah melahirkan lokakarya khusus di konferensi ML terkemuka seperti sebagai ICML.Catatan kaki13 Beberapa metode yang menjanjikan untuk interpretabilitas telah dikembangkan sampai sekarang, mulai dari paket perangkat lunak untuk lokal, model agnostik yang dapat dijelaskan (misalnya, Ribeiro et al. 2016 ) untuk berbagai macam model, melalui pendekatan teori permainan untuk kemampuan menjelaskan (misalnya, Lundberg dan Lee 2017 ) untuk metode kemampuan menjelaskan, yang dikembangkan khusus untuk interpretasi JST (misalnya, Kokhlikyan et al. 2019 ). Karena ada banyak kemungkinan untuk memasukkan metode yang dapat dijelaskan hari ini, kami sangat menyarankan untuk menggunakan metode ini. Pertama, mereka membantu ilmuwan membuat model yang lebih baik dan meningkatkan hasil dan kedua, mereka dapat membantu meningkatkan kepercayaan pengulas dalam metodologi.Implikasi untuk penelitian dan praktikImplikasi untuk penelitian ISDue to the outlined points, scholars face a huge challenge to publish ML papers in high-level IS-journals because the reviewers are aware of these problems. Although the submitted works could provide interesting results, they can be rejected by the reviewers because i) the expert sees a trade-off of rigor for relevance, ii) a deeper understanding of analytical procedures is difficult or impossible due to a black box characteristic, iii) traceability of the methodology is impossible due to data pre-processing, parameter tweaking or overfitting. We believe that this is one of the profound explanations for the small number of high-level publications containing ML methods in the IS research domain. On a different note, a publicly accessible scientometrics project that analyzed Computer Science publications between 2012 and 2017Footnote14 revealed that 28,303 papers which dealt with topics in the field of ML were published in this timeframe alone. Computer Science deals with the improvement of algorithms, IS applies them (if they are contextually appropriate) to solve problems or gain new insights. We, therefore, hope that our paper provides a fresh impetus to researchers to not only increase their chances of acceptance by describing their methodology in using ML methods more thoroughly but also to improve our understanding of the results from ML in IS research in general, such that result reproducibility will lead to consequent cutting-edge research projects.Implications for practiceIn principle, ML methods are promising for optimizing processes, products, services, or for supporting management decisions through inferential statistical analyses (Baesens et al. 2016, p. 810). However, as soon as the results of the ML methods have to be understood by third parties in the company who do not have the expertise in the statistical procedures on which the ML methods are based, the methods lose credibility and usefulness in practice due to the black box problem. This poses the central problem of the interpretability of the results for the application of ML methods in the business sector. For business managers, it is important to understand the recommendations; therefore, the results must either be self-explanatory or easily traceable (Bose and Mahapatra 2001, p. 215). This circumstance is especially dangerous for middle-sized organizations and organizations with lower IT expertise. These organizations are under increasing pressure to develop technologies that allow them to compete within their market, especially with regard to the penetration of different industries by IT companies (Kohli and Melville 2018, p. 1). As a particular example that shows how traditional players can be threatened by IT-driven companies which focus on novel technologies and their technological expertise, the market disruption in payment transactions could be mentioned, which was disrupted by the ascent of technology firms like Apple (Puschmann 2017, p. 69). To come back to the problems of the application of ML methods in the business context. On the one hand, the management of traditional industry companies do not embrace the technologies and do not completely tap their full potential. On the other hand, high-tech companies like Amazon dedicate a lot of financial and human resources to the development of systems with ML applications, e.g., to increase satisfaction in customer service (Nwankpa and Datta 2017, p. 472). This discrepancy in the strategies of traditional industry players and IT-players may lead to an outflow of knowledge, the missing out on game-changing opportunities, and finally, the loss of competitiveness with all its economic consequences (Krauss et al. 2017, p. 48). Further researchThe findings of our bibliographic bibliographic review suggest that IS research has been reluctant to apply ML methods within research articles, especially regarding publications in high to top-ranking journals. This also implies that a far-reaching fundamental understanding of the chances and risks of applying ML methods has not yet been developed within our research domain. Generally speaking, IS research needs to engage further with ML and its applications on socio-technical problems that we face in our research discipline, to understand the opportunities and risks in the innovation context. As a hyphenated research domain between management and Computer Science, IS research needs to face the challenges and opportunities of ML methods and provide this knowledge to other scholars in social sciences and other management disciplines. Our results indicate that the majority of scholars in the IS research domain follow the classical (quantitative analysis) approach, which is founded on hypothesis-based research. Following that finding, an overarching challenge arises in IS because ML is often used as part of an outright different approach. Regarding the example of pattern recognition, a general idea may arise that certain sample data could provide new insights for a specific research case, yet a hypothesis may not be put forward unless the data has been analyzed and patterns have been found within the data. In consequence, and in line with Maass et al. (2018), matches between two different approaches that rectify the application of ML methods based on theory must be found. Hence, an important challenge is that bridging the gap between the data-driven and the theory-driven research models requires researchers to engage in tasks for which no single individual may be perfectly equipped because they require knowledge and skills related to data analytics techniques, as well as expertise in relevant domain theories (Maass et al. 2018, p. 1259). Subsequently, further research needs to deal with the gap between hypothesis-based research and the pattern recognition approach for ML. The two approaches should be extensively tested and evaluated in business and industry applications where productive problem solving and decision-making with Computational Intelligence (e.g., Sha et al. 2019, p. 108), ML and Soft Computing methods (e.g., Ibrahim 2016, p. 34) can be set up, implemented, carried out and evaluated. Accepted, conservative (hypothesis-driven) methods may follow the IS paradigms but will be meaningless if they appear unable to handle real-world problems in a digital economy and Big Data context. In consequence, IS research has to address several questions that allow a theoretical foundation for research to be built that embraces ML as a powerful research instrument in IS, and which coincides with the requirements of Maass et al. (2018) in the context of data-driven and theory-driven research:
3) Tentang temuan kami dari RQ 1.1 dan RQ 1.2, kami menyusun kerangka kerja penelitian Sistem Informasi awal berdasarkan karya Hevner et al. ( 2004 ). Gambar 4 menunjukkan kerangka kerja kami. kerja ini bertujuan untuk mengatasi empat pertanyaan dasar yang disebutkan sebelumnya untuk mendukung penerimaan yang luas dan aplikasi terstruktur dari metode ML dalam penelitian IS. Kerangka penelitian pada gagasan bahwa penelitian SI biasanya mencakup kebutuhan bisnis dan pengembangan teori dari teori-teori yang ada dan bertujuan untuk membenarkan teori-teori ini dengan menganalisis kumpulan data menggunakan dan instrumen klasik. Dalam proses pembenaran, sekali lagi, pengetahuan dasar dan metodologi ML dapat meningkatkan kekayaan dan kekuatan instrumen analitik dan memberikan wawasan yang inovatif, dibandingkan dengan instrumen analitik klasik. Selain itu, ketika mencoba mengumpulkan wawasan baru tentang fenomena yang berkaitan dengan sistem berbasis ML secara langsung, mungkin bermanfaat untuk memodifikasi sistem tersebut, selain mengamati dan menganalisis fenomena dengan sistem berbasis ML sebagai artefak TI yang jauh dan statis. Meskipun orang mungkin berpendapat bahwa metodologi klasik (yaitu, studi kasus, eksperimen Wizard of Oz) mungkin cukup kuat untuk mengamati fenomena tertentu, masuk akal untuk mengasumsikan, bagaimanapun, bahwa mampu menyesuaikan perilaku sistem berbasis ML, baik itu dalam eksperimen (lapangan, laboratorium) , studi kasus atau penelitian desain tindakan, setidaknya akan drastis meningkatkan validitas eksternal temuan. Pada temuannya, penelitian IS dapat mengarah pada dorongan baru untuk penerapan ML di domain industri yang relevan. Sebaliknya, aspek teori yang muncul dari penerapan praktis metode ML tertentu dapat bekerja sebagai peningkatan pengetahuan dasar untuk dasar pengetahuan ML.Akhirnya, kami percaya bahwa dengan menerapkan metode ML untuk masalah bisnis, teori penelitian SI bermanfaat bagi organisasi dan masyarakat. KesimpulanTinjauan bibliografi dan analisis scientometrik kami bertujuan untuk memajukan pemahaman kami tentang kemunculan makalah penelitian tentang ML dalam bidang IS. Makalah ini juga bertujuan untuk menyadarkan IS tentang penerapan metode ML berdasarkan bibliografi kami di jurnal IS tingkat tinggi. Kami dua memeriksa penelitian untuk memahami keadaan penelitian ML terapan saat ini di bidang pertanyaan IS. Sebagai langkah pertama untuk membuat pembaca peka dengan masalah yang ada di ML, kami memberikan pengenalan dan gambaran umum tentang topik terkait AI dan ML, metode ML yang berbeda, koneksinya, kelebihan, kekurangan, dan keterbatasannya. Kami melanjutkan dengan dan bibliografi berdasarkan Senior Scholars Basket of Journals di IS (misalnya, Trieu2017 ; Khan dan Triers 2018 ) ditambah Jurnal Pasar Elektronik dan Sistem Pendukung Keputusan sebagai proxy untuk jurnal terpenting dalam domain penelitian kami. Kami memeriksa 1.919 artikel dan menemukan 441 artikel yang menggunakan ML dalam enam database penelitian penting dalam rentang waktu 2009-2019. Namun, kami hanya menemukan sejumlah kecil artikel tentang penerapan metode ML di jurnal IS peringkat atas dalam bibliografi bibliografi kami. Kami menyimpulkan bahwa kurangnya kepercayaan dan keahlian dalam metode ML mungkin menjadi alasan utama untuk jarangnya penerapan ML (canggih).Kesimpulan ini didasarkan pada kombinasi bibliografi kami, analisis scientometrik, dan temuan survei nasional kami terhadap sarjana IS di Jerman. Dari semua sarjana yang berpartisipasi, 93,22% tidak memiliki kursus ML yang diperlukan selama PhD, tetapi 74,07 % ingin kursus seperti itu. Detail ini sangat relevan, karena sebagian besar peserta survei menyatakan bahwa mereka harus bekerja dengan ML selama studi dan penelitian PhD mereka (berbagi lebih tinggi hingga sangat tinggi: 59,6%, vs tanpa aplikasi: 3,85%), sementara hanya 35, 48% peserta memiliki ML yang meningkat atau tinggi dalam studi mereka (Sarjana/Diploma/Magister).Karena kurangnya pelatihan dalam ini, kurangnya dasar kepercayaan, keyakinan, dan keahlian pada prinsipnya tidak dapat dikesampingkan, yang meningkatkan ketidakpastian dengan metode yang lebih tinggi dan kemampuan interpretasi yang lebih rendah, dan dapat menyebabkan lebih sedikit penerapan metode tersebut. metode (misalnya, Pajares karena sebagian besar peserta survei menyatakan bahwa mereka harus bekerja dengan ML selama studi dan penelitian PhD mereka (berbagi lebih tinggi hingga sangat tinggi: 59,6%, vs tidak ada aplikasi: 3,85%), sementara hanya 35 ,48% peserta yang mengalami peningkatan atau bagian ML yang tinggi dalam studi mereka (Sarjana/Diploma/Magister).Karena kurangnya pelatihan dalam ini, kurangnya dasar kepercayaan, keyakinan, dan keahlian pada prinsipnya tidak dapat dikesampingkan, yang meningkatkan ketidakpastian dengan metode yang lebih tinggi dan kemampuan interpretasi yang lebih rendah, dan dapat menyebabkan lebih sedikit penerapan metode tersebut. metode (misalnya, Pajares karena sebagian besar peserta survei menyatakan bahwa mereka harus bekerja dengan ML selama studi dan penelitian PhD mereka (berbagi lebih tinggi hingga sangat tinggi: 59,6%, vs tidak ada aplikasi: 3,85%), sementara hanya 35 ,48% peserta yang mengalami peningkatan atau bagian ML yang tinggi dalam studi mereka (Sarjana/Diploma/Magister).Karena kurangnya pelatihan dalam ini, kurangnya dasar kepercayaan, keyakinan, dan keahlian pada prinsipnya tidak dapat dikesampingkan, yang meningkatkan ketidakpastian dengan metode yang lebih tinggi dan kemampuan interpretasi yang lebih rendah, dan dapat menyebabkan lebih sedikit penerapan metode tersebut. metode (misalnya, Pajares 1996 , hal. 551). sebagian besar jurnal penelitian IS tingkat tinggi hanya sedikit kontribusi untuk memperkenalkan metode ML yang baru dan inovatif untuk penelitian IS. Berdasarkan hasil kami, Keranjang Jurnal Cendekia Senior di IS memulai animasi. Sejauh pengetahuan kami, kami adalah orang pertama yang menyebutkan masalah ini dengan sangat jelas. Hebatnya, panggilan yang dijanjikan untuk makalah tentang AI dan ML (misalnya, Berente et al. 2019 ; Jain et al. 2018 ) baru-baru ini muncul, menunjukkan bahwa beberapa jurnal tingkat tinggi juga telah menyadari masalah tersebut dan menawarkan untuk mengatasinya. itu dengan upaya yang Secara keseluruhan, ML telah berkembang secara dramatis selama dua dekade terakhir menjadi teknologi kunci komersial yang tersebar luas (Jordan dan Mitchell 2015 , hlm. 255). Disiplin seperti Ilmu Komputer memimpin dalam domain penelitian ini. Namun demikian, sarjana IS, baik yang mahir atau tertarik dalam penerapan ML, menuntut pengembangan lebih lanjut secara eksplisit dari teknologi yang dijanjikan ini, karena mereka dapat mengarah pada wawasan baru dan memungkinkan pendekatan yang berbeda dari metode kuantitatif klasik (Sallesa et al. (Sallesa et al. 2017 , p .40); Didimoa dkk. ( 2018 , hlm. 83); Gao dkk. ( 2017 , hlm. 180); Zimbra dkk. ( 2017 , hlm. 108); Abbasi dkk. (2010 , hlm. 485 )). Karena metodologis serta haus datanya, pilihan metode ML mungkin, bagi banyak sarjana, tidak muncul pendekatan yang optimal untuk penelitian IS. Seperti yang ditunjukkan dalam makalah kami, metode ML berkembang pada kumpulan besar data yang bersih dan terstruktur dengan baik untuk pelatihan dan pengujian. Jenis data ini lebih mudah ditemukan dalam konteks teknik dan dihasilkan oleh otomatisasi dan/atau teknologi berbasis sensor dibandingkan dalam konteks bisnis atau sosial ekonomi. Dalam hal ini dan terlepas dari metode tradisional dan ML, para sarjana yang tersebar menerapkan metode bidang Soft Computing (SC) dan Computational Intelligence (CI) ke masalah sosial-ekonomi dengan sukses besar. CI, sebagai paradigma komputasi di bidang ML, telah mencapai peningkatan substansial di berbagai bidang berdasarkan kemampuan untuk mempelajari tugas-tugas tertentu dari data atau pengamatan eksperimental (Sha et al. 2019 , hlm. 108). Dengan komputasi tradisional, komputasi yang berbeda dengan model kehidupan dan memberikan solusi untuk masalah nyata yang kompleks. Tidak seperti komputasi keras, komputasi lunak untukleran terhadap ketidaktepatan, ketidakpastian, kebenaran parsial, dan perkiraan (Ibrahim 2016 , hal. 34). Selain dikembangkan dan diterapkan di bidang teknik, CI dan SC kini berkembang pesat juga untuk tujuan manajemen dan bisnis, terutama dalam paradigma analitik, yang kini tumbuh kuat dan cepat dalam permintaan dalam bisnis dan industri (Davenport 2006 ). Pemeriksaan teknologi ini menawarkan nilai bisnis yang tinggi (Collins et al. 2010 , hlm. 433). Baik CI maupun SC kurang sensitif terhadap kualitas data yang digunakan untuk pelatihan dan pengujian. Algoritma makro-heuristik cepat dan kurang bersifat kotak hitam daripada metode ML yang lebih kompleks.Penelitian kritis di masa depan dapat mengeksplorasi sejauh mana CI dan SC dapat meningkatkan keterbatasan dalam penerapan dan transparansi yang ditemukan untuk metode ML yang kompleks. Namun demikian dan mirip dengan kedudukan ML dalam penelitian IS, artikel termasuk metodologi SC atau CI mungkin juga lebih jarang ditemukan di jurnal dalam Keranjang Cendekia Senior karena dewan editorial menyadari tidak menyadari metode yang relatif baru dan kuat ini. . Hasil penyelidikan kami menjamin pekerjaan lebih lanjut di bidang ini sejak panggilan pertama untuk tindakan menangani ML dalam penelitian IS sudah muncul dua dekade lalu (Wong et al. 1997 ). Oleh karena itu, kami meminta komunitas IS untuk memperkuat upaya penerapan terkait penerapan ML dan melakukan penelitian menyeluruh untuk memverifikasi hasil yang diberikan oleh pendekatan ini. Selanjutnya, kami mengundang sesama cendekiawan dan peneliti dari domain kami untuk menangani pertanyaan mendasar untuk penelitian ML terapan di IS (Tabel 4 ), yang dihasilkan dari analisis kami dan refleksi mereka.Mungkin, penyertaan ML yang lebih kuat sebagai instrumen pelengkap untuk metode penelitian saat ini - baik itu studi kasus, penelitian desain tindakan, atau eksperimen - bahkan dapat memiliki tren transformatif dari monometodologi ke peningkatan studi multimetodologi dengan wawasan yang lebih mendalam. Untuk menyimpulkan, penelitian kami menunjukkan bahwa penelitian IS hanya pada awal mengeksploitasi dan mengeksplorasi potensi penuh dari metode ML untuk tujuan ilmiah. Kami yakin bahwa, dengan membangun fondasi dengan hasil penelitian terverifikasi dan menjawab pertanyaan mendasar sebagai langkah pertama, SI dan peneliti dari disiplin ilmu ekonomi lainnya mungkin akan lebih memanfaatkan metode ML. Pada akhirnya, ini dapat membawa penelitian di bidang IS dan ekonomi ke tingkat baru yang dapat menciptakan wawasan yang sebelumnya tidak dapat dicapai.elumnya tidak dapat dicapai. sumber : Referensi
https://link.springer.com/article/10.1007/s12525-021-00459-2 |