|
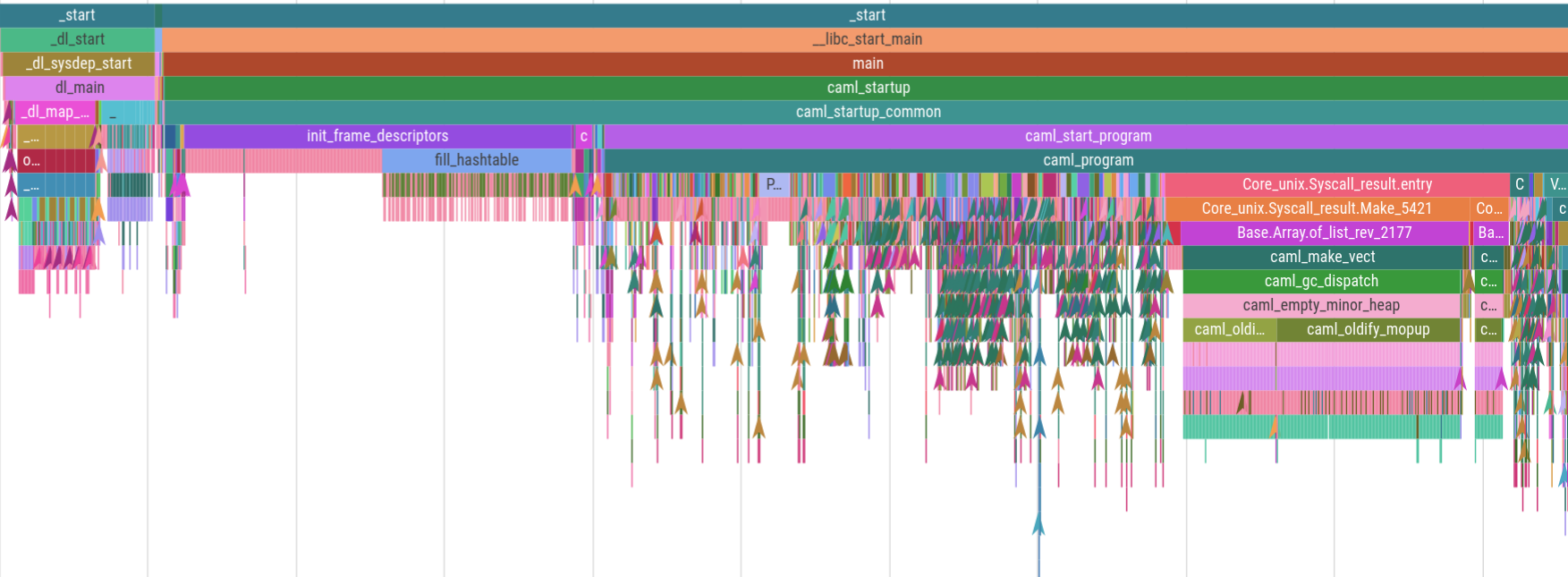
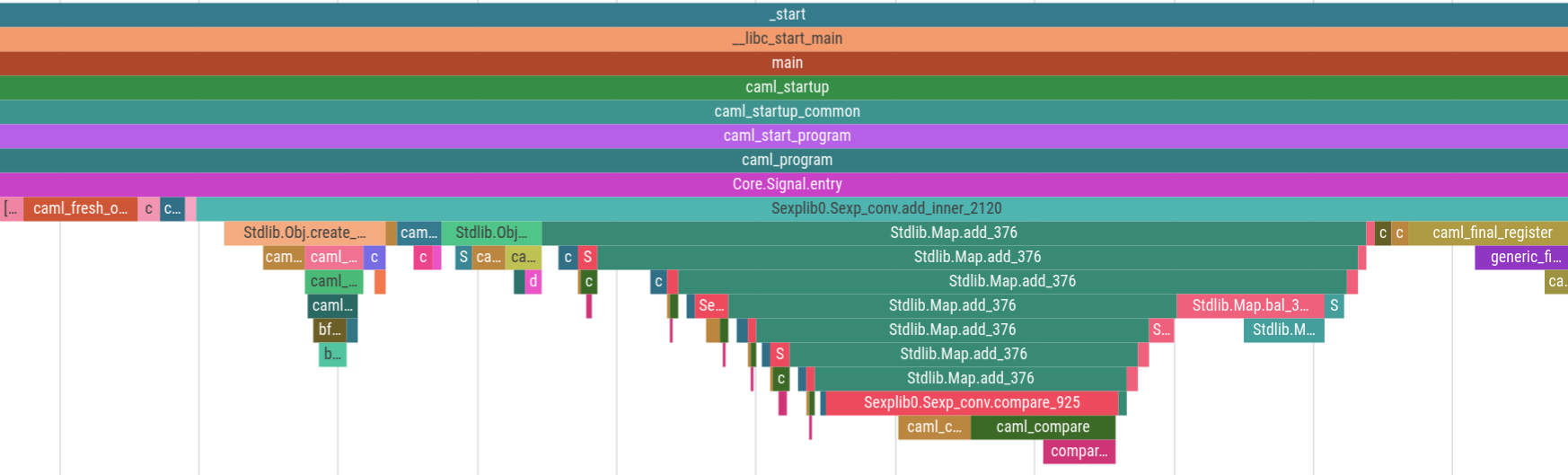
Pelacakan Prosesor Intel adalah teknologi perangkat keras yang dapat merekam semua aliran eksekusi program bersama dengan informasi pengaturan waktu yang akurat hingga sekitar 30ns. Sejauh yang saya tahu hampir tidak ada yang menggunakannya , tampaknya karena menangkap data itu rumit dan, tanpa alat visualisasi apa pun, Anda terpaksa membaca tumpukan teks yang sangat besar. Magic-trace adalah alat yang kami buat dan bersumber terbuka untuk memudahkan menangkap jejak sekitar 10 md yang mengarah ke panggilan fungsi yang Anda pilih untuk instrumen, lalu memvisualisasikan tumpukan panggilan pada garis waktu tempat Anda dapat memperbesar dan melihat setiap panggilan fungsi dan berapa lama waktu yang dibutuhkan. Berikut adalah jejak yang diambil dari 5 ms startup program OCaml:
Dan inilah jejak yang sama yang diperbesar menjadi 500 nanodetik. Peristiwa merah tipis adalah 1-3 nanodetik:
Baru-baru ini kami menggunakan alat ini untuk mendiagnosis masalah kinerja yang akan sangat sulit dipecahkan dengan alat lain. Menggunakannya semudah menambahkan Magic_trace.take_snapshotpanggilan ke kode Anda (atau menggunakan fuzzy-finder untuk memilih fungsi yang ada), lalu jalankan magic-trace attachdan gunakan fuzzy-finder untuk memilih proses Anda. Itu akan mengeluarkan jejak yang dapat Anda lihat di penampil jejak Perfetto Google . Dalam posting ini kita akan membahas mengapa Pelacakan Prosesor begitu istimewa, kesulitan membangun sesuatu di atas teknologi perangkat keras yang hampir tidak digunakan oleh siapa pun, bagaimana kita diserang oleh bug kernel dan bug perangkat keras, dan jenis masalah yang kita hadapi. sudah bisa dipecahkan dengan alat tersebut. Mengapa Pelacakan Prosesor Intel, dan mengapa tidak?Mari kita lihat jenis-jenis utama alat analisis kinerja dan mengapa magic-trace melayani ceruk yang berbeda: Pengambilan sampel profiler menginterupsi program setiap 250 mikrodetik atau lebih, mengambil sampel tumpukan panggilan saat ini, lalu meringkas semuanya. Ini bagus untuk memberi Anda gambaran di mana program Anda menghabiskan waktunya. Namun, di Jane Street kami memiliki banyak sistem perdagangan berkinerja tinggi yang menghabiskan hampir seluruh waktunya menunggu paket jaringan yang ingin kami tanggapi dalam waktu kurang dari interval pengambilan sampel 250 mikrodetik. Profiler pengambilan sampel kira-kira tidak berguna untuk mendiagnosis masalah latensi pada skala itu: Anda akan beruntung mendapatkan satu sampel dalam kode yang Anda minati! Bahkan dalam sistem yang lebih tradisional, Anda mungkin ingin mendiagnosis peristiwa latensi ekor pendek namun jarang, atau memperhatikan perbedaan antara fungsi yang dipanggil 10 kali lebih banyak dari yang Anda harapkan atau satu panggilan ke sana membutuhkan waktu 10 kali lebih lama dari yang diharapkan, yang dapat dilakukan oleh profiler pengambilan sampel. tidak memberitahumu. Pelacakan berbasis instrumentasi baik menambal atau mengompilasi probe ke dalam program yang mencatat kapan fungsi tertentu dimulai dan diakhiri, lalu biasanya memvisualisasikannya pada UI garis waktu interaktif. Kami menggunakan kembali UI dari sistem pelacakan Perfetto untuk pelacakan sihir, meskipun kami perlu melakukan fork untuk menangani peristiwa dengan lebih baik dalam skala nanodetik tunggal. Sistem penelusuran berperforma tinggi seperti tracy bahkan berhasil menurunkan biaya overhead menjadi sekitar 2ns per panggilan (kami membuat sistem serupa untuk OCaml dan membuka sumbernya). Namun, menginstrumentasi setiap fungsi berisiko (mis. Anda dapat melipatgandakan biaya fungsi 1ns yang dipanggil di mana-mana) jadi biasanya fungsi tersebut memerlukan instrumentasi manual, dan terkadang masalah kinerja Anda ada di aplikasi atau fungsi yang belum dianotasi. Pelacakan perangkat keras seperti Pelacakan Prosesor Intel (IPT) memiliki keunggulan pelacakan tetapi tidak memerlukan instrumentasi apa pun, dan dapat memiliki biaya overhead yang jauh lebih rendah daripada menginstrumentasi semuanya. Mereka menggunakan format yang sangat efisien yang hanya menyandikan informasi yang cukup untuk merekonstruksi aliran kontrol – misalnya cabang bersyarat membutuhkan satu bit. Overhead waktu untuk IPT bervariasi dari 2-20% tergantung pada programnya, dengan setiap program kami yang telah saya tolok ukur mengalami penurunan kurang dari 10% dan biasanya di bawah 5%. Ada beberapa kelemahan dari Processor Trace:
Produk minimum yang layakSelama magang musim panas 2021 Jane Street , saya berbicara dengan beberapa kolega tentang masalah kami yang membuat profil segmen waktu menarik yang sangat singkat. Saya mencatat bahwa Jejak Prosesor Intel akan bagus untuk ini tetapi sangat sulit untuk digunakan. Kemudian saya menyadari bahwa dengan pustaka visualisasi pelacakan yang baru saja saya tulis, dan beberapa fitur dari dokumentasi Pelacakan Prosesor yang baru saja saya baca, saya dapat melihat jalur ke alat yang mudah digunakan. Jadi saya menyusun dokumen proyek magang baru, dan untuk paruh kedua magangnya, Chris Lambert dan saya bekerja untuk menyusunnya. Gagasan utama di balik membuat alat yang berguna dengan cepat adalah membatasi ruang lingkup:
Tahap pertama adalah mengimplementasikan alat sebagai pembungkus di sekitar perffungsionalitas Pelacakan Prosesor alat Linux, dan Chris merintisnya dalam waktu kurang dari seminggu. Mengirim SIGUSR2sinyal perf menyebabkannya mengambil snapshot, jadi Chris menulis Magic_trace.take_snapshotfungsi yang dikirim SIGUSR2ke pid induk. Kemudian dia menulis parser dan pembuat ulang tumpukan panggilan untuk mengubah tumpukan perf scriptteks semua cabang menjadi jejak yang menangani fitur OCaml seperti panggilan ekor dan beberapa pengecualian. Sangat menyenangkan melihat melalui jejak pertama dan dapat memperbesar dan melihat detail terkecil, dan segera memperhatikan hal-hal seperti itu waktu mulai program OCaml sebagian besar terdiri dari kesalahan halaman penginisialisasi modul di bagian acak biner. Langsung menggunakan API kernel dan libiptKemudian kami memulai sesuatu yang lebih sulit. Mem-parsing output perf alat lambat dan tidak dapat melakukan decoding tingkat instruksi yang diperlukan untuk menangani push dan pop dengan benar ke tumpukan penangan pengecualian OCaml. Kami memutuskan untuk mencoba langsung menggunakan kernel perf_event_open API dan libipt decoding library Intel. Ini ternyata cukup rumit, karena kami tidak dapat menemukan bukti yang pernah dicoba diintegrasikan secara langsung oleh siapa pun perf_event_opensebelumnya libipt. Saya akhirnya menghabiskan hari-hari saya mempelajari dokumentasi dan kode sumber libiptdan perfalat untuk mencari tahu bagaimana melakukan hal-hal yang belum kami pahami dan menyerahkan jawaban dan tautan contoh kepada Chris, yang menulis dan men-debug kode C untuk berinteraksi dengan API dan dengan OCaml. Setelah banyak penelitian dan debugging, pada akhir magang kami berhasil mendapatkan jejak peristiwa dari implementasi awal kami. Setelah Chris pergi, saya men-debug masalah yang tersisa dan memasukkannya sepenuhnya. Mudah-mudahan sekarang kami telah menerbitkan basis kode referensi, siapa pun yang mencoba ini akan lebih mudah. Breakpoint perangkat keras untuk pemicuan yang lancarSetelah Chris pergi dan semuanya berfungsi, fitur terbesar yang perlu kami jadikan berguna dan mudah adalah kemampuan untuk melampirkan ke proses yang ada. Sayangnya ini merusak SIGUSR2pensinyalan snapshot berbasis induk kami. Saya ingin Magic_trace.take_snapshotmemiliki overhead yang mendekati nol sementara magic-tracetidak terpasang, dan overhead rendah bahkan ketika itu memicu snapshot. Saya pikir saya mungkin harus meminta setiap proses menghosting server IPC kecil atau menggunakan ptrace , tetapi saya tidak senang dengan solusi tersebut. Saya menghabiskan banyak waktu mencari solusi yang lebih baik dan akhirnya saya menemukan solusi yang sangat memuaskan di perf_event_open docs. Ternyata perf_event_openbisa menggunakan breakpoint perangkat keras dan memberi tahu Anda saat alamat memori dijalankan atau diakses. Yang keren dari pendekatan ini adalah tidak memerlukan kerja sama dari target, tidak ada overhead saat tidak terpasang, dan sebenarnya bisa digunakan pada fungsi apa pun yang kita inginkan, bukan hanya Magic_trace.take_snapshotfungsi khusus. Saat kami menggunakannya pada fungsi khusus, kami dapat mengambil sampel register sehingga kami dapat melihat argumen yang digunakan untuk memanggilnya, memungkinkan pengguna untuk menyertakan metadata dengan snapshot mereka. Saya pikir itu mengatakan sesuatu yang menarik tentang estetika pemrograman saya bahwa saya menghabiskan sepanjang hari untuk meneliti alternatif untuk menambahkan server IPC kecil dan akhirnya menggunakan API kernel khusus dan fitur perangkat keras. Saya tahu perangkat keras memungkinkan desain yang tidak memerlukan kompilasi ulang atau penambahan tambahan untuk proses yang tidak dilacak, dan saya benar-benar ingin membuat penggunaan pertama kali sehalus mungkin dan menghindari membengkaknya program orang lain. Jika saya benar-benar mengikuti rute IPC, saya setidaknya akan menggunakan soket domain abstrak khusus Linux yang kurang jelas tetapi masih langka (dinamai oleh PID) untuk menghindari keharusan membersihkan file atau berurusan dengan port. Terkadang pendekatan standar tidak dapat membawa Anda ke pengalaman pengguna yang ideal, tetapi lebih mudah dipertahankan oleh rekan kerja Anda, Anda mengalami lebih sedikit masalah, dan perlu melakukan lebih sedikit penelitian. Pengorbanan ini menyisakan buah yang menggantung rendah bagi orang-orang yang senang menyelam jauh ke dalam dokumentasi yang tidak jelas dan men-debug masalah-masalah aneh, yang dapat memberi keseimbangan. Breakpoint perangkat keras, keseluruhanmagic-traceproyek, dan proyek saya yang lain adalah hasil dari kesenangan bertanya pada diri sendiri "dapatkah saya melenyapkan masalah ini dengan bersedia melakukan hal-hal terkutuk?" Bug kernel dan bug perangkat keras, bahaya menjadi lebih awalOrang-orang kadang-kadang menggunakan Pelacakan Prosesor, dan sebagian besar berfungsi, tetapi saya telah belajar bahwa ketika menggunakan ceruk dan perangkat keras baru yang rumit, saya tidak dapat memiliki prioritas rendah yang sama seperti yang biasanya saya lakukan tentang bug yang disebabkan oleh kernel atau perangkat keras. Saya sangat senang dapat mencoba debugging kernel untuk pertama kalinya ketika saya menemukan cara untuk membuat crash kernel menggunakan kombinasi fitur Pelacakan Prosesor yang tidak biasa. Saya menggunakan info dari dump inti kernel, dan membaca jalur aliran kontrol dan tambalan terbaru di kernel, untuk mencari tahu alasan akses penunjuk nol. Ternyata tambalan menambahkan bendera yang membuat satu bagian negara tidak valid untuk diakses, tetapi gagal menjaganya dengan pernyataan if di satu tempat. Persis jenis bug yang jenis data aljabar di OCaml/Rust/etc membantu Anda menghindari :) Bug lain jauh lebih misterius dan sulit. Tepat pada satu program dari semua yang saya coba, Pelacakan Prosesor secara misterius akan berhenti menambahkan peristiwa ke buffer pelacakan sebelum mencapai titik snapshot. Saya menghabiskan 2 minggu untuk menambahkan berbagai jenis kemampuan observasi dan memperbaiki masalah lain yang menghalangi (setidaknya begitumagic-trace berakhir lebih baik bagaimanapun juga), dan tidak dapat menemukan penyebab perangkat lunak yang masuk akal, misalnya sakelar konteks yang sejalan dengan saat perekaman berhenti. Akhirnya saya mencoba menjalankannya pada prosesor Intel generasi yang lebih baru dan masalahnya hilang. Saya menduga itu mungkin Intel erratum SKL171 "Intel® PT May Drop All Packets After Internal Buffer Overflow" yang terjadi di bawah "kondisi mikroarsitektur yang langka", meskipun mungkin masih ada bug kernel kondisi ras yang sangat konsisten hanya di perangkat keras yang lebih lama . Memecahkan masalah rumitOrang-orang baru menggunakan magic-tracesecara internal selama sekitar satu bulan, tetapi kami telah memanfaatkannya dengan baik. Tujuan desain aslinya adalah untuk membantu mengatasi masalah kinerja dalam sistem perdagangan berkinerja tinggi yang tidak dapat dilakukan oleh pembuat sampel sampel, dan itu berhasil. Ini membantu mengidentifikasi regresi kinerja 100ns yang disebabkan oleh tambalan yang ternyata menyebabkan pemanggilan fungsi tidak digariskan. Itu juga membantu mendiagnosis mengapa versi kompiler baru membuat sistem perdagangan lebih lambat, yang ternyata juga menghasilkan keputusan inlining. Tapi setelah kami membuat magic-trace, kami menyadari itu bisa membantu masalah kinerja sulit lainnya yang sering dihadapi orang-orang di Jane Street. Kami menggunakan Async untuk menangani banyak tugas bersamaan secara kooperatif. Bagian "kooperatif" berarti bahwa jika satu tugas memakan waktu terlalu lama maka semua tugas lainnya harus menunggunya. Jika Anda memiliki masalah yang menyebabkan tugas menangani lebih banyak pekerjaan dari biasanya, ini dapat menyebabkan "siklus asinkron yang panjang". Ini bisa sangat sulit untuk di-debug jika hanya terjadi sesekali, karena Anda tidak mendapatkan info apa pun tentang kode apa yang terlalu lambat. Sebelumnya orang-orang terpaksa menangkap perfprofil panjang yang sangat besar dan kemudian menggunakan stempel waktu monoton yang dicatat untuk memfilter profil ke wilayah yang relevan. Sekarang dengan magic-traceorang-orang cukup menambahkan potongan kode yang memanggil Magic_trace.take_snapshotsetelah siklus selama jangka waktu tertentu, lalu lampirkan magic-tracedan tunggu sampai ditangkap. Bahkan jika siklus panjang adalah 15 detik, 10 milidetik terakhir dari pekerjaan biasanya merupakan kumpulan besar pekerjaan yang sama, jadi Anda dapat melihat kembali jejak untuk melihat kode mana yang melakukan terlalu banyak pekerjaan. Kami telah menggunakan ini untuk memecahkan satu masalah rumit di mana ada lebih banyak item dalam koleksi tertentu dari yang diharapkan dan satu putaran menghabiskan beberapa detik untuk mengerjakannya. Pemfilteran profil sampel akan lebih sulit dan tidak akan dapat mengetahui apakah fungsi tersebut terlalu sering diulang alih-alih, katakanlah, memakan waktu sangat lama sekali atau hanya selalu agak lambat. Meskipun magic-tracehanya diperlukan untuk kode kinerja tinggi tertentu, sebagai alat kinerja yang ramah pengguna di kotak peralatan, ini dapat berguna untuk semua jenis masalah debug dan kinerja hanya dengan lebih cepat dan lebih mudah digunakan daripada alternatif. Bagaimana Anda bisa menggunakan magic-traceKami merancang magic-trace untuk kode OCaml kami sendiri, tetapi sekarang Anda dapat menggunakannya pada setiap native executable dengan nama simbol (misalnya program C++ atau Rust) selama Anda memiliki mesin Intel Linux yang cukup baru. Begini caranya: # If this prints 1 your machine supports Processor Trace with precise timingcat /sys/bus/event_source/devices/intel_pt/caps/psb_cyc# Install Opam (https://opam.ocaml.org/doc/Install.html), then OCaml 4.12.1opam switch create 4.12.1opam switch 4.12.1# Add the Jane Street pre-release repo, magic-trace isn't on public Opam yetopam repo add janestreet-bleeding https://ocaml.janestreet.com/opam-repository# Install the magic-trace command line toolopam install magic-trace# This lets you fuzzy-search a process to attach to and a symbol to snapshot onmagic-trace attach -symbol '' -output magic.ftf# Go to https://ui.perfetto.dev/ and open the trace fileTidak ada orang lain yang pernah menggunakan Perfetto untuk jejak seperti ini sebelumnya, jadi kami juga harus meninggalkan ekstensi OCaml dan C kami ke tanah TypeScript dan menambal Perfetto untuk mendukung pembesaran ke tingkat nanodetik . UI Perfetto utama berfungsi , dan kami berharap dapat melakukan upstream beberapa tambalan ke sana, tetapi untuk pengalaman terbaik, Anda dapat membuat UI dari fork kami. Mari gunakan lebih banyak Pelacakan Prosesor!Pelacakan Prosesor Intel adalah teknologi yang sangat kuat dan keren, dan sayang sekali bahwa lebih banyak orang tidak menggunakannya. Saya harap magic-traceini menunjukkan kepada orang-orang betapa bergunanya Processor Trace dan teknologi seperti itu, dan membuatnya lebih mudah untuk menggunakan Processor Trace dengan memberikan contoh basis kode. Salah satu cara untuk membuat alat di atas Pelacakan Prosesor yang belum saya sebutkan adalah perf-dlfilter , yang memungkinkan Anda mengonsumsi perfperistiwa menggunakan C API yang efisien dengan pustaka bersama daripada mem-parsing keluaran teks. Kami tidak menggunakannya karena baru saja dikirimkan ke kernel saat kami sedang menulis magic-trace; kami tidak mempelajarinya sampai saya menemukannya beberapa bulan kemudian. Saya akan merekomendasikan bahwa alat mencoba untuk memulai dengan perfand dlfilterdaripada perf_event_opendan libipt, karena alat ini hanya mengimplementasikan banyak hal yang harus Anda terapkan kembali. Di akhir masa magangnya, Chris bahkan menyarankan bahwa dengan melihat ke belakang kita seharusnya bercabang perfuntuk menambahkan antarmuka C daripada memulai libiptrute – dan untungnya orang lain melakukannya, dengan tujuan khusus untuk membaca peristiwa Pelacakan Prosesor secara efisien! Anda bahkan tidak memerlukan kernel super baru, karena Anda dapat mengkompilasi perf alat dari pohon kernel yang lebih baru dan menggunakannya pada kernel yang lebih lama. Berikut adalah beberapa ide lain yang telah kami pikirkan untuk perkakas Pelacakan Prosesor yang belum dibuat oleh siapa pun dan yang mungkin akan kami kembangkan magic-trace:
sumber : https://blog.janestreet.com/magic-trace/ |